RBO & CBO优化器
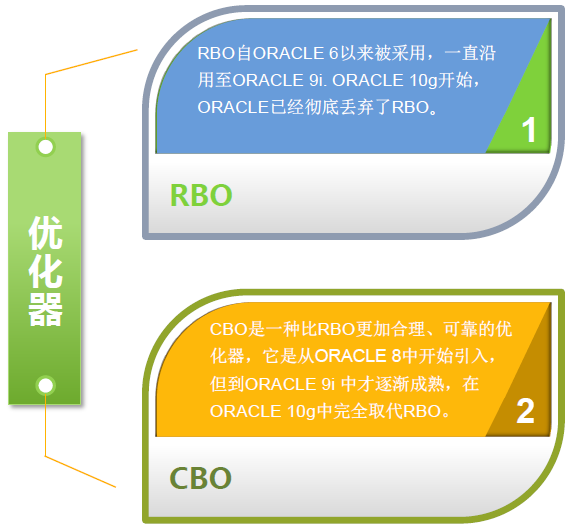
- RBO有着一套严格的使用规则,只要你按照它去写SQL语句,无论数据表中的内容怎样,也不会影响到你的“执行计划”,也就是说RBO对数据不“敏感”,它根据ORACLE指定的优先顺序规则,对指定的表进行执行计划的选择。比如在规则中,索引的优先级大于全表扫描。RBO是根据可用的访问路径以及访问路径等级来选择执行计划。在RBO中,SQL的写法往往会影响执行计划。
- CBO(Cost-Based Optimizer)是计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。如果对一次执行SQL时发现涉及对象(表、索引等)没有被分析、统计过,那么ORACLE会采用一种叫做动态采样的技术,动态的收集表和索引上的一些数据信息。
基于规则的优化器 - RBO
在判断最优查询路径时以这些定义好的优先顺序为规则
- 使用ROWID读取一行数据
- 依据聚簇连接读取一行数据
- 依据Unique HASH Cluster读取一行数据
- 依据Unique INDEX读取一行数据
- CLUSTER连接
- Non Unique HASH CLUSTER Key
- Non Unique CLUSTER Key
- Non Unique组合索引
- Non Unique 单一列索引
- 依据索引的范围查询
- 依据索引的整体范围查询
- Sort Merge连接
- 索引列的MIN、MAX计算
- 索引列的ORDER BY
- 全表扫描
注:红色是常用的规则
基于RBO的测试
构建测试环境conn lyj/lyj
create table t10(id int, name varchar(100));
begin
for i in 1 .. 10000 loop
insert into t10 values(i,'lyj'||i);
end loop;
commit;
end;
/
create index idx_t10_id on t10(id);
exec dbms_stats.gather_table_stats(user,'T10',cascade=>true);
测试一(CBO)explain plan for select * from t10 where id>=1 and id<=100;
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1113277928
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 1200 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T10 | 100 | 1200 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T10_ID | 100 | | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=1 AND "ID"<=100)
14 rows selected.
测试二(CBO)explain plan for select * from t10 where id>=1 and id<=8000;
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 2919944937
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8001 | 96012 | 9 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T10 | 8001 | 96012 | 9 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"<=8000 AND "ID">=1)
13 rows selected.
测试三(RBO)explain plan for select /*+ index(t10 idx_t10_id) */ * from t10 where id>=1 and id<=8000;
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1113277928
------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8001 | 96012 | 38 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T10 | 8001 | 96012 | 38 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_T10_ID | 8001 | | 18 (0)| 00:00:01 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID">=1 AND "ID"<=8000)
14 rows selected.
CBO误区
- 不同SQL文本的Cost是不可比较的
- 统计信息就是指柱状图
- 执行计划突然错误, 分析柱状图就可以解决所有问题
- 绑定变量可以减少硬解析, 任何时候都应该使用它
- /+NO_MERGE/是不使用归并连接
理解CBO
CBO可能会把SQL进行等价转换(所见非所得),借助Oracle的10053事件event,可以监控到CBO对SQL进行成本计算和路径选择的过程和方法。
CBO将系统I/O和CPU转化为统一的成本度量,比较多条可能的执行路径成本差额,最后将成本cost最少的一个作为实际生成的执行计划。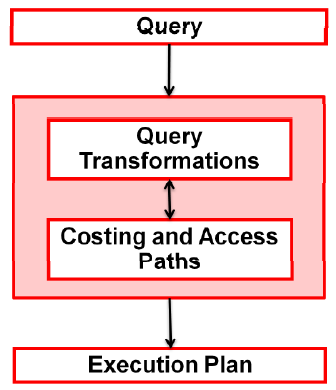
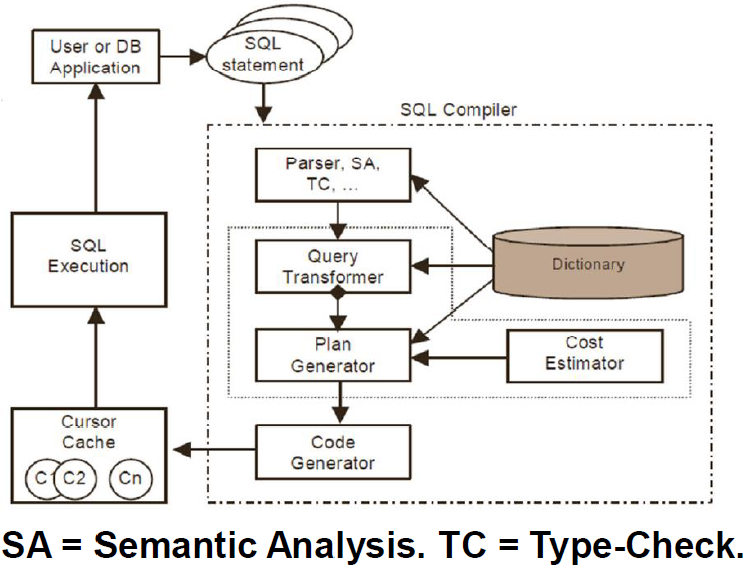
CBO成本计算
- 统计信息:与SQL语句所引用的对象相关,以及主机的CPU和IO
- SQL语句本身
- 数据库实例环境,例如与优化器相关的参数设置
- optimizer_features_enable – 限定优化器的特性支持到特定的Oracle版本
- optimizer_index_caching – 用于在执行in-list遍历和嵌套循环连接时,优化器评估已经存在于buffer cache中的索引块的数量(以百分比的方式)。参数的取值范围是0到100,默认值为0,取值越大就越减少优化器在评估In-list和嵌套循环连接的索引扫描的开销COST
- optimizer_index_cost_adj – 优化器计算通过索引扫描访问表数据的cost开销,可以通过这个参数进行调整。参数可用值的范围为1到10000。默认值为100,超过100后越大则越会使索引扫描的COST开销越高(计算的),从而导致查询优化器更加倾向于使用全表扫描。相反,值越小于100,计算出来的索引扫描的开销就越低。
- optimizer_mode: ALL_ROWS(注重吞吐量-OLAP,默认值)、FIRST_ROWS_N(注重响应时间-OLTP)
SQL> show parameter optimizer NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ optimizer_capture_sql_plan_baselines boolean FALSE optimizer_dynamic_sampling integer 2 optimizer_features_enable string 11.2.0.4 optimizer_index_caching integer 0 optimizer_index_cost_adj integer 100 optimizer_mode string ALL_ROWS optimizer_secure_view_merging boolean TRUE optimizer_use_invisible_indexes boolean FALSE optimizer_use_pending_statistics boolean FALSE optimizer_use_sql_plan_baselines boolean TRUE
CBO的核心概念

执行计划
执行计划是数据库访问操作的一组有序集合,是指导数据库对数据进行读取的算法。
查看执行计划的方法explain plan for select * from t10 where id>=1 and id<=8000;
select * from table(dbms_xplan.display);
单表访问路径
- 全表扫描(Full Table Scan)
- 索引范围扫描(Index Range Scan)
- 索引快速全扫描(Fast Full Index Scan)
- 索引全扫描(Index Full Scan)
Costing Model 成本模型

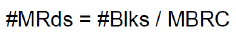
解释Cost = IO Cost + CPU Cost
= (单块读IO次数*单块读时间 + 多块读IO次数*多块读时间 +
CPU周期/CPU速度) / 单块读的时间
单块读时间 = IO磁盘寻道时间 + 数据块大小 / IO传输速度
多块读时间 = IO磁盘寻道时间 + 多块读一次数量(db_file_multiblock_read_count) * 数据块大小 / IO传输速度
多块读次数 = 总的块数 / MBRC(db_file_multiblock_read_count)
SQL> show parameter db_file_multiblock_read_count
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128
-- CPUCycles(CPU周期)等于PLAN_TABLE里面的CPU_COST
explain plan for select count(*) from t10;
select cpu_cost from plan_table where object_name='T10';
CPU_COST
----------
1699400
-- CPUSPPED(CPU速度)
SQL> select pname,pval1 from sys.aux_stats$ where sname='SYSSTATS_MAIN';
PNAME PVAL1
------------------------------ ----------
CPUSPEEDNW 1200 --每秒的操作次数
IOSEEKTIM 10 --IO磁盘寻道时间
IOTFRSPEED 4096 --IO传输速度
SREADTIM
MREADTIM
CPUSPEED --表示CPU每秒的转速(在操作平台上每秒执行校准操作的次数)
MBRC
MAXTHR
SLAVETHR
全表扫描成本公式

全表扫描的时候,单块读次数=0,#SRds表示单块读次数。全表扫描的成本里面,CPU消耗其实非常少,可以忽略不计,所以全表扫描的公式可以改写为:Cost = #MRds * mreadtim / sreadtim
索引范围扫描成本公式
cost = blevel + celiling(leaf_blocks *effective index selectivity) + celiling(clustering_factor * effective table selectivity) cost = 索引高度 + celiling(叶子块*索引选择率) + celiling(聚簇因子*表选择率) |

索引快速全扫描成本公式
Cost ≈ Leaf Bolcks / db_file_multiblock_read_count
|
Clustering_factor聚簇因子
- 聚簇因子(Clustering_factor)是使用B树索引进行区间扫描的成本很重要因素,反映数据在表中分布的随机程序
- 聚簇因子的计算方法是扫描索引比较某行的ROWID和前一行的ROWID,如果这两个ROWID不属于同一个数据块,那么聚簇因子增加1,整个索引扫描完毕后,就得到了该索引的聚簇因子
- 对选择最优查询路径影响最大的只有列的选择率和聚簇因子
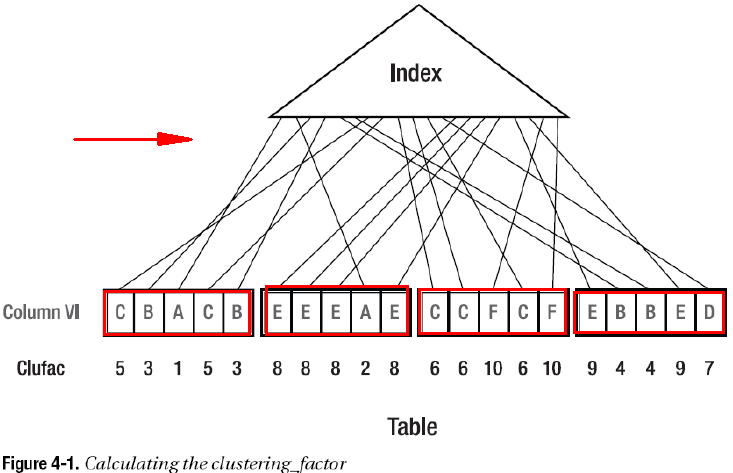
SQL> select NUM_ROWS,BLOCKS from user_tables where TABLE_NAME='T10'; NUM_ROWS BLOCKS ---------- ---------- 10000 28 SQL> select CLUSTERING_FACTOR from user_indexes where TABLE_NAME='T10'; CLUSTERING_FACTOR ----------------- 24 --当CLUSTERING_FACTOR和BLOCKS接近时, 说明表中数据分布有序 --当CLUSTERING_FACTOR和NUM_ROWS接近时,说明表中数据分布很乱,最好用move等命令进行优化 |
嵌套循环连接成本公式
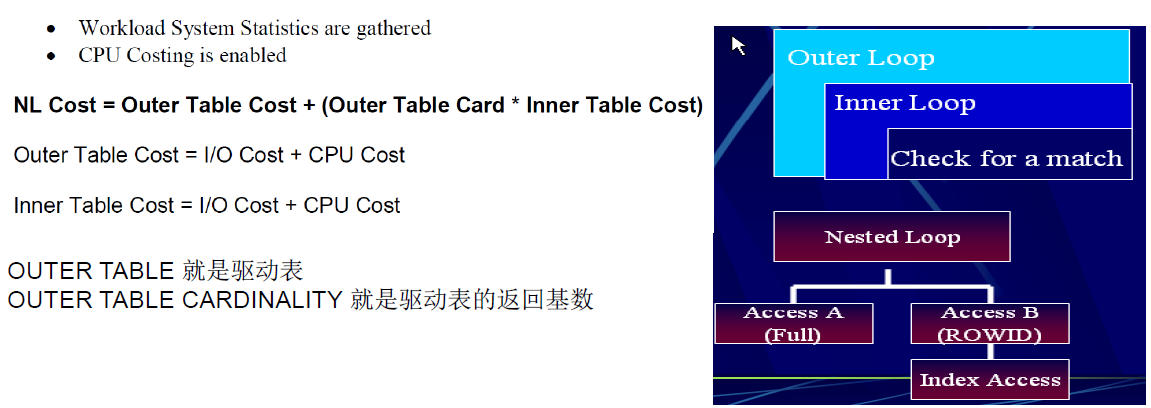
哈希连接成本公式

排序合并连接成本公式

选择率 - Selectivity
计算依据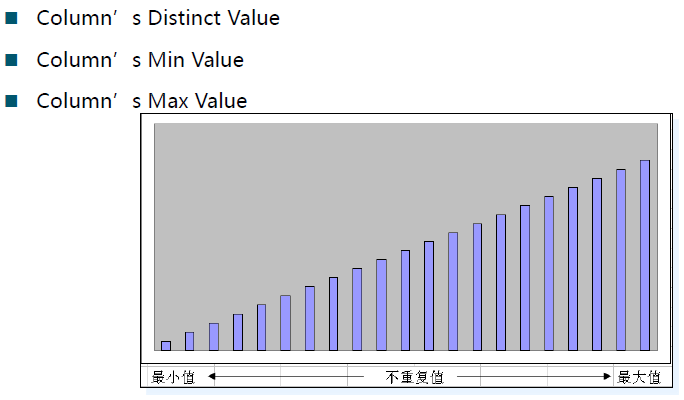
选择率是指满足条件的行在查询的结果集中所占的比率,即满足需求的行数 / 可用的总行数Selectivity = "required range" divided by "total available range"
多表连接Selectivity
基数 - Cardinality

Oracle经典的查询转换
视图合并(view merge)
如果不进行视图合并,那么这个视图就会当成一整块,在SQL执行过程中,这个视图会被当成一个结果集,然后再去和别的表/结果集关联。
如果进行了视图合并,那么这个视力就不会当成一整块了,它会被拆散,分开的执行。CBO通常情况下认为视图进行合并之后,性能较高,所以一般情况下都会发生视图合并。但是并不是每次进行了视图合并性能就高,所以在进行SQL优化的时候要特别留意视图合并。
视图合并(view merge)试验-- 视图合并
explain plan for SELECT to_char(wmsys.wm_concat(a.TABLE_NAME))
FROM user_tables a, dba_objects b
WHERE a.TABLE_NAME = b.OBJECT_NAME
AND b.OWNER = 'LYJ'
AND B.OBJECT_TYPE = 'TABLE';
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 2990975862
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 203 | 297 (2)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 203 | | |
|* 2 | HASH JOIN | | 1211 | 240K| 297 (2)| 00:00:04 |
|* 3 | VIEW | DBA_OBJECTS | 1596 | 75012 | 51 (2)| 00:00:01 | -- 执行计划中只能看到DBA_OBJECTS视图
| 4 | UNION-ALL | | | | | |
|* 5 | TABLE ACCESS BY INDEX ROWID | SUM$ | 1 | 26 | 0 (0)| 00:00:01 | -- USER_TABLES视图被合并
|* 6 | INDEX UNIQUE SCAN | I_SUM$_1 | 1 | | 0 (0)| 00:00:01 |
|* 7 | FILTER | | | | | |
|* 8 | HASH JOIN | | 1595 | 182K| 51 (2)| 00:00:01 |
| 9 | INDEX FULL SCAN | I_USER2 | 36 | 756 | 1 (0)| 00:00:01 |
| 10 | NESTED LOOPS | | 1595 | 149K| 50 (2)| 00:00:01 |
| 11 | TABLE ACCESS BY INDEX ROWID| USER$ | 1 | 18 | 1 (0)| 00:00:01 |
|* 12 | INDEX UNIQUE SCAN | I_USER1 | 1 | | 0 (0)| 00:00:01 |
|* 13 | TABLE ACCESS FULL | OBJ$ | 1595 | 121K| 49 (3)| 00:00:01 |
| 14 | NESTED LOOPS | | 1 | 28 | 2 (0)| 00:00:01 |
|* 15 | INDEX SKIP SCAN | I_USER2 | 1 | 19 | 1 (0)| 00:00:01 |
|* 16 | INDEX RANGE SCAN | I_OBJ4 | 1 | 9 | 1 (0)| 00:00:01 |
|* 17 | FILTER | | | | | |
|* 18 | HASH JOIN | | 1 | 97 | 1 (0)| 00:00:01 |
| 19 | TABLE ACCESS BY INDEX ROWID | USER$ | 1 | 18 | 1 (0)| 00:00:01 |
|* 20 | INDEX UNIQUE SCAN | I_USER1 | 1 | | 0 (0)| 00:00:01 |
| 21 | INDEX FULL SCAN | I_LINK1 | 1 | 79 | 0 (0)| 00:00:01 |
|* 22 | HASH JOIN OUTER | | 1211 | 184K| 245 (1)| 00:00:03 |
|* 23 | HASH JOIN RIGHT OUTER | | 1211 | 178K| 232 (1)| 00:00:03 |
| 24 | INDEX FULL SCAN | I_USER2 | 36 | 108 | 1 (0)| 00:00:01 |
|* 25 | HASH JOIN OUTER | | 1211 | 175K| 231 (1)| 00:00:03 |
|* 26 | HASH JOIN | | 1211 | 165K| 218 (1)| 00:00:03 |
| 27 | TABLE ACCESS FULL | TS$ | 8 | 24 | 5 (0)| 00:00:01 |
|* 28 | HASH JOIN RIGHT OUTER | | 1211 | 162K| 213 (1)| 00:00:03 |
| 29 | TABLE ACCESS FULL | SEG$ | 2833 | 31163 | 27 (0)| 00:00:01 |
| 30 | NESTED LOOPS | | 1211 | 149K| 186 (2)| 00:00:03 |
| 31 | MERGE JOIN CARTESIAN | | 1596 | 152K| 49 (3)| 00:00:01 |
|* 32 | HASH JOIN | | 1 | 68 | 0 (0)| 00:00:01 |
|* 33 | FIXED TABLE FULL | X$KSPPI | 1 | 55 | 0 (0)| 00:00:01 |
| 34 | FIXED TABLE FULL | X$KSPPCV | 100 | 1300 | 0 (0)| 00:00:01 |
| 35 | BUFFER SORT | | 1596 | 47880 | 49 (3)| 00:00:01 |
|* 36 | TABLE ACCESS FULL | OBJ$ | 1596 | 47880 | 49 (3)| 00:00:01 |
|* 37 | TABLE ACCESS CLUSTER | TAB$ | 1 | 28 | 1 (0)| 00:00:01 |
|* 38 | INDEX UNIQUE SCAN | I_OBJ# | 1 | | 0 (0)| 00:00:01 |
| 39 | INDEX FAST FULL SCAN | I_OBJ1 | 14362 | 112K| 13 (0)| 00:00:01 |
| 40 | INDEX FAST FULL SCAN | I_OBJ1 | 14362 | 71810 | 13 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
....
-- 视图不合并
explain plan for SELECT /*+ no_merge(a) */ to_char(wmsys.wm_concat(a.TABLE_NAME))
FROM user_tables a, dba_objects b
WHERE a.TABLE_NAME = b.OBJECT_NAME
AND b.OWNER = 'GYJ'
AND B.OBJECT_TYPE = 'TABLE';
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 3297109666
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 66 | 297 (2)| 00:00:04 |
| 1 | SORT AGGREGATE | | 1 | 66 | | |
|* 2 | HASH JOIN | | 1211 | 79926 | 297 (2)| 00:00:04 |
| 3 | VIEW | USER_TABLES | 1211 | 23009 | 245 (1)| 00:00:03 | -- 执行计划中会有两个视图,USER_TABLES
|* 4 | HASH JOIN OUTER | | 1211 | 184K| 245 (1)| 00:00:03 |
|* 5 | HASH JOIN RIGHT OUTER | | 1211 | 178K| 232 (1)| 00:00:03 |
| 6 | INDEX FULL SCAN | I_USER2 | 36 | 108 | 1 (0)| 00:00:01 |
|* 7 | HASH JOIN OUTER | | 1211 | 175K| 231 (1)| 00:00:03 |
|* 8 | HASH JOIN | | 1211 | 165K| 218 (1)| 00:00:03 |
| 9 | TABLE ACCESS FULL | TS$ | 8 | 24 | 5 (0)| 00:00:01 |
|* 10 | HASH JOIN RIGHT OUTER | | 1211 | 162K| 213 (1)| 00:00:03 |
| 11 | TABLE ACCESS FULL | SEG$ | 2833 | 31163 | 27 (0)| 00:00:01 |
| 12 | NESTED LOOPS | | 1211 | 149K| 186 (2)| 00:00:03 |
| 13 | MERGE JOIN CARTESIAN | | 1596 | 152K| 49 (3)| 00:00:01 |
|* 14 | HASH JOIN | | 1 | 68 | 0 (0)| 00:00:01 |
|* 15 | FIXED TABLE FULL | X$KSPPI | 1 | 55 | 0 (0)| 00:00:01 |
| 16 | FIXED TABLE FULL | X$KSPPCV | 100 | 1300 | 0 (0)| 00:00:01 |
| 17 | BUFFER SORT | | 1596 | 47880 | 49 (3)| 00:00:01 |
|* 18 | TABLE ACCESS FULL | OBJ$ | 1596 | 47880 | 49 (3)| 00:00:01 |
|* 19 | TABLE ACCESS CLUSTER | TAB$ | 1 | 28 | 1 (0)| 00:00:01 |
|* 20 | INDEX UNIQUE SCAN | I_OBJ# | 1 | | 0 (0)| 00:00:01 |
| 21 | INDEX FAST FULL SCAN | I_OBJ1 | 14362 | 112K| 13 (0)| 00:00:01 |
| 22 | INDEX FAST FULL SCAN | I_OBJ1 | 14362 | 71810 | 13 (0)| 00:00:01 |
|* 23 | VIEW | DBA_OBJECTS | 1596 | 75012 | 51 (2)| 00:00:01 | -- 和DBA_OBJECTS
| 24 | UNION-ALL | | | | | |
|* 25 | TABLE ACCESS BY INDEX ROWID | SUM$ | 1 | 26 | 0 (0)| 00:00:01 |
|* 26 | INDEX UNIQUE SCAN | I_SUM$_1 | 1 | | 0 (0)| 00:00:01 |
|* 27 | FILTER | | | | | |
|* 28 | HASH JOIN | | 1595 | 182K| 51 (2)| 00:00:01 |
| 29 | INDEX FULL SCAN | I_USER2 | 36 | 756 | 1 (0)| 00:00:01 |
| 30 | NESTED LOOPS | | 1595 | 149K| 50 (2)| 00:00:01 |
| 31 | TABLE ACCESS BY INDEX ROWID| USER$ | 1 | 18 | 1 (0)| 00:00:01 |
|* 32 | INDEX UNIQUE SCAN | I_USER1 | 1 | | 0 (0)| 00:00:01 |
|* 33 | TABLE ACCESS FULL | OBJ$ | 1595 | 121K| 49 (3)| 00:00:01 |
| 34 | NESTED LOOPS | | 1 | 28 | 2 (0)| 00:00:01 |
|* 35 | INDEX SKIP SCAN | I_USER2 | 1 | 19 | 1 (0)| 00:00:01 |
|* 36 | INDEX RANGE SCAN | I_OBJ4 | 1 | 9 | 1 (0)| 00:00:01 |
|* 37 | FILTER | | | | | |
|* 38 | HASH JOIN | | 1 | 97 | 1 (0)| 00:00:01 |
| 39 | TABLE ACCESS BY INDEX ROWID | USER$ | 1 | 18 | 1 (0)| 00:00:01 |
|* 40 | INDEX UNIQUE SCAN | I_USER1 | 1 | | 0 (0)| 00:00:01 |
| 41 | INDEX FULL SCAN | I_LINK1 | 1 | 79 | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------------
谓词推进(Predicate Pushing)
当SQL语句中包含有不能合并的视图,并且视图有谓语过滤(也就是WHERE过滤条件),CBO会将WHERE过滤条件推入视图中,这个就叫做谓词推进。谓词推进的主要目的就是让Oracle尽可能早的过滤掉无用的数据,从而提升查询性能。create or replace view emp12 as select /*+ NO_MERGE */ ename,job,deptno from emp where sal>(select avg(sal) from emp);
explain plan for select * from emp12 where job='ANALYST';
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1573522662
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 6 (0)| 00:00:01 |
| 1 | VIEW | EMP12 | 1 | 26 | 6 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | EMP | 1 | 39 | 3 (0)| 00:00:01 | -- 谓词推进EMP表
| 3 | SORT AGGREGATE | | 1 | 13 | | |
| 4 | TABLE ACCESS FULL| EMP | 14 | 182 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("JOB"='ANALYST' AND "SAL"> (SELECT AVG("SAL") FROM
LYJ."EMP" "EMP"))
create or replace view emp11 as select ename,job,deptno from emp where sal>(select avg(sal) from emp) and rownum>=1;
explain plan for select * from emp11 where job='ANALYST';
select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 2936634123
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 6 (0)| 00:00:01 |
|* 1 | VIEW | EMP11 | 1 | 26 | 6 (0)| 00:00:01 | -- 谓词没有推进
| 2 | COUNT | | | | | |
|* 3 | FILTER | | | | | |
|* 4 | TABLE ACCESS FULL | EMP | 1 | 39 | 3 (0)| 00:00:01 |
| 5 | SORT AGGREGATE | | 1 | 13 | | |
| 6 | TABLE ACCESS FULL| EMP | 14 | 182 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("JOB"='ANALYST')
3 - filter(ROWNUM>=1)
4 - filter("SAL"> (SELECT AVG("SAL") FROM LYJ."EMP" "EMP"))
子查询非嵌套化(Subquery Unnesting)
如果SQL语句中的WHERE条件后面有子查询,子查询前面有in, not in, exists, not exists, <, <=, =, >, >=等等,CBO很可能会对该子查询进行等价改写,改写的过程其实就叫做子查询扩展。Oracle始终认为SQL语句进行改写之后,CBO能更好的优化,当然,并不是所有的子查询都会被改写,子查询中有些限制条件会阻止CBO进行改写(因为改写之后不等价)explain plan for select * from emp where deptno in(select deptno from dept where dname='SALES');
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY(NULL, NULL, 'ADVANCED -PROJECTION'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 2125045483
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 545 | 6 (17)| 00:00:01 |
| 1 | MERGE JOIN | | 5 | 545 | 6 (17)| 00:00:01 |
|* 2 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 22 | 2 (0)| 00:00:01 |
| 3 | INDEX FULL SCAN | DEPT_PK | 4 | | 1 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 14 | 1218 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 1218 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$5DA710D3
2 - SEL$5DA710D3 / DEPT@SEL$2
3 - SEL$5DA710D3 / DEPT@SEL$2
5 - SEL$5DA710D3 / EMP@SEL$1
explain plan for select * from emp where deptno in(select /*+ NO_UNNEST */ deptno from dept where dname='SALES');
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY(NULL, NULL, 'ADVANCED -PROJECTION'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 963670887
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 1218 | 4 (0)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | TABLE ACCESS FULL | EMP | 14 | 1218 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 22 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | DEPT_PK | 1 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$1
2 - SEL$1 / EMP@SEL$1
3 - SEL$2 / DEPT@SEL$2
4 - SEL$2 / DEPT@SEL$2
OR条件展开
select sal from emp where job='CLERK' or deptno=10; ==> select sal from emp where job='CLERK' UNION ALL select sal from emp where deptno=10 and job<>'CLERK'; |
绑定变量
- 作用:绑定变量可以减少硬解析
- 副作用:使用绑定变量除了以上可以避免硬解析的好处之外,还有其自身的缺陷,就是这种纯绑定变量的使用适合于绑定变量列值比较均匀分布的情况,如果绑定变量列值有一些非均匀分布的特殊值,就可能会造成非高效的执行计划被选择(在生成执行的时候可能不够优化,固化了执行计划)
绑定变量的窥探
Oracle在处理带有绑定变量的SQL时候,只会在硬解析的时候才会“窥探”一下SQL中绑定变量的值,然后会根据窥探到的值来决定整个SQL的执行计划。参数:_optim_peek_user_binds
绑定变量窥探案例
构建测试数据conn lyj/lyj
create table t8(id int ,name varchar2(100));
begin
for i in 1 .. 10 loop
insert into t8 values(i,'B');
end loop;
commit;
end;
/
begin
for i in 11 .. 100010 loop
insert into t8 values(i,'A');
end loop;
commit;
end;
/
col name for a10
select name,count(*) from t8 group by name;
NAME COUNT(*)
---------- ----------
A 100000
B 10
create index t_idx on t8(name);
收集统计信息begin
dbms_stats.gather_table_stats(ownname=>'LYJ',
tabname=>'T8',
cascade=>true);
end;
/
没有绑定变量的执行计划select * from t8 where name='A';
select * from table(dbms_xplan.display_cursor);
#==================================================================================
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 61x85hfmkf5n3, child number 0
-------------------------------------
select * from t8 where name='A'
Plan hash value: 3870692729
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 70 (100)| |
|* 1 | TABLE ACCESS FULL| T8 | 100K| 683K| 70 (3)| 00:00:01 | -- 全表扫描
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NAME"='A')
#==================================================================================
select * from t8 where name='B';
select * from table(dbms_xplan.display_cursor);
#==================================================================================
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 387rqpyaau6ag, child number 0
-------------------------------------
select * from t8 where name='B'
Plan hash value: 2794484989
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID| T8 | 18 | 126 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 18 | | 1 (0)| 00:00:01 | -- 索引范围扫描
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("NAME"='B')
#==================================================================================
-- 执行下面的语句可以看到,上面的两个SQL各被硬解析1次
col SQL_TEXT for a50
select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select * from t8%';
#==================================================================================
SQL_TEXT SQL_ID VERSION_COUNT
-------------------------------------------------- ------------- -------------
select * from t8 where name='A' 61x85hfmkf5n3 1
select * from t8 where name='B' 387rqpyaau6ag 1
#==================================================================================
使用绑定变量的执行计划-- 先清空一下
alter system flush buffer_cache;
alter system flush shared_pool;
variable c varchar2(100);
exec :c := 'A';
select * from t8 where name = :c;
select * from table(dbms_xplan.display_cursor);
#==================================================================================
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 83q59jq0sx58q, child number 0
-------------------------------------
select * from t8 where name = :c
Plan hash value: 3870692729
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 70 (100)| |
|* 1 | TABLE ACCESS FULL| T8 | 99992 | 683K| 70 (3)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NAME"=:C)
#==================================================================================
exec :c := 'B';
select * from t8 where name = :c;
select * from table(dbms_xplan.display_cursor);
#==================================================================================
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 83q59jq0sx58q, child number 0
-------------------------------------
select * from t8 where name = :c
Plan hash value: 3870692729
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 70 (100)| |
|* 1 | TABLE ACCESS FULL| T8 | 99992 | 683K| 70 (3)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("NAME"=:C)
#==================================================================================
-- 如果数据库版本是ORACLE 10G,有绑定变量窥探问题,SQL的执行计划取决于第一次硬解析时窥探的值
-- 执行下面的语句可以看到,上面的两个SQL只被硬解析1次
col SQL_TEXT for a50
select sql_text,sql_id,version_count from v$sqlarea where sql_text like 'select * from t8%';
#==================================================================================
SQL_TEXT SQL_ID VERSION_COUNT
-------------------------------------------------- ------------- -------------
select * from t8 where name = :c 83q59jq0sx58q 2
#==================================================================================
收集直方图,然后后再查name = :c的执行计划BEGIN
DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'LYJ',
tabname => 'T8',
estimate_percent => 100,
method_opt => 'for all columns size skewonly',
no_invalidate => FALSE,
degree => 1,
cascade => TRUE);
END;
/
select * from t8 where name = :c;
select * from table(dbms_xplan.display_cursor);
#==================================================================================
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 83q59jq0sx58q, child number 1
-------------------------------------
select * from t8 where name = :c
Plan hash value: 2794484989
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 2 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID| T8 | 18 | 126 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 18 | | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("NAME"=:C)
#==================================================================================
-- 绑定变量窥探的情况下,可以利用到直方图,Oracle 11g中的adaptive cursor sharing能区别绑定敏感游标和非敏感游标
直方图
- 直方图是优化器使用的一种统计数据,里面可以看出记录的分布情况
- 作用:当某列数据分布不均衡时,为了让CBO能生成最佳的执行计划,可能需要对表收集直方图,真方图最大的桶数(Bucket)是254
- 两种直方图
- 频率直方图,当列中Distinct_key小于254,Oralce就会自动创建频率直方图,并且桶数(Bucket)等于Distinct_key
- 高度直方图,当列中Distinct_key大于254,Oralce就会自动创建高度平衡直方图
- 收集直方图是一个很耗时的过程,如无必要,千万别去收集直方图
-- 生成直方图 BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'LYJ', tabname => 'T8', estimate_percent => 100, method_opt => 'for all columns size 254', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; / -- 删除直方图 BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname=> 'LYJ', tabname => 'T8', estimate_percent => 100, method_opt => 'for all columns size 1', -- 删除时size设置为1 no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /
统计信息
自动收集统计信息
-- 默认情况下,Oracle启动了统计信息的自动收集功能 select client_name,status from dba_autotask_client; #================================================================================== CLIENT_NAME STATUS ---------------------------------------------------------------- -------- auto optimizer stats collection ENABLED -- 启动了统计信息的自动收集功能 auto space advisor ENABLED sql tuning advisor ENABLED #================================================================================== -- 查看统计信息自动启动时间 select client_name,max(job_start_time) from dba_autotask_job_history group by client_name; #================================================================================== CLIENT_NAME MAX(JOB_START_TIME) ---------------------------------------- ---------------------------------------- auto optimizer stats collection 26-JUL-18 10.00.01.267145 PM PRC auto space advisor 26-JUL-18 10.00.01.282452 PM PRC sql tuning advisor 26-JUL-18 10.00.01.281525 PM PRC #================================================================================== -- 具体设置 col WINDOW_NAME for a20 col REPEAT_INTERVAL for a60 col DURATION for a30 set linesize 120 SELECT t1.window_name, t1.repeat_interval, t1.duration,enabled FROM dba_scheduler_windows t1, dba_scheduler_wingroup_members t2 WHERE t1.window_name = t2.window_name AND t2.window_group_name IN ('MAINTENANCE_WINDOW_GROUP', 'BSLN_MAINTAIN_STATS_SCHED'); #================================================================================== WINDOW_NAME REPEAT_INTERVAL DURATION ENABL -------------------- ------------------------------------------------------------ ------------------------------ ----- MONDAY_WINDOW freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE TUESDAY_WINDOW freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE WEDNESDAY_WINDOW freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE THURSDAY_WINDOW freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE FRIDAY_WINDOW freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 +000 04:00:00 TRUE SATURDAY_WINDOW freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 +000 20:00:00 TRUE SUNDAY_WINDOW freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 +000 20:00:00 TRUE #================================================================================== -- 关闭自动收集统计信息,自动收集统计信息会消耗一部分系统资源,如果没有必要可以关闭该功能 begin dbms_auto_task_admin.disable( client_name=>'auto optimizer stats collection', operation=>null,window_name=>null); end; / select client_name,status from dba_autotask_client; #================================================================================== CLIENT_NAME STATUS ---------------------------------------- -------- auto optimizer stats collection DISABLED auto space advisor ENABLED sql tuning advisor ENABLED #================================================================================== -- 启用自动收集统计信息 begin dbms_auto_task_admin.enable( client_name=>'auto optimizer stats collection', operation=>null,window_name=>null); end; / |
手动收集统计信息
手动收集统计信息的场景:
- 数据量修改很频繁的表
- 直方图
- 收集某些固定表的统计信息
BEGIN DBMS_STATS.GATHER_TABLE_STATS( ownname => 'LYJ', tabname => 'T8', estimate_percent => dbms_stats.auto_sample_size, method_opt => 'for all columns size repeat', cascade => TRUE); END; /
过时的统计信息
statistrics_level: TYPICAL or ALLconn / as sysdba
show parameter statistics_level
#==================================================================================
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
statistics_level string TYPICAL
#==================================================================================
create table t20 as select * from dba_objects where rownum<=500;
exec dbms_stats.gather_table_stats('SYS','T20');
select num_rows,blocks,stale_stats from user_tab_statistics where table_name='T20';
#==================================================================================
NUM_ROWS BLOCKS STA
---------- ---------- ---
500 7 NO
#==================================================================================
insert into t20 select * from t20;
commit;
select num_rows,blocks,stale_stats from user_tab_statistics where table_name='T20';
#==================================================================================
NUM_ROWS BLOCKS STA
---------- ---------- ---
500 7 NO
#==================================================================================
exec dbms_stats.flush_database_monitoring_info;
col TABLE_NAME for a10
col PARTITION_NAME for a15
col SUBPARTITION_NAME for a15
select * from user_tab_modifications where table_name='T20';
#==================================================================================================================
TABLE_NAME PARTITION_NAME SUBPARTITION_NA INSERTS UPDATES DELETES TIMESTAMP TRU DROP_SEGMENTS
---------- --------------- --------------- ---------- ---------- ---------- ------------------- --- -------------
T20 500 0 0 2018-07-27 17:16:52 NO 0
#==================================================================================================================
begin
dbms_stats.gather_schema_stats(
ownname=>'SYS',
options=>'GATHER STALE');
end;
/
select num_rows,blocks,stale_stats from user_tab_statistics where table_name='T20';
#==================================================================================================================
NUM_ROWS BLOCKS STA
---------- ---------- ---
1000 15 NO
#==================================================================================================================
动态抽样
optimizer_dynamic_sampling: 可以将它设置为0-10,默认值是2,它指示优化器仅对未分析的表进行少量数据块抽样show parameter optimizer_dynamic_sampling
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_dynamic_sampling integer 2
临时表的地方必须用动态采样,写上HINT强制它采样/*+ dynamic_sampling(t 0) */
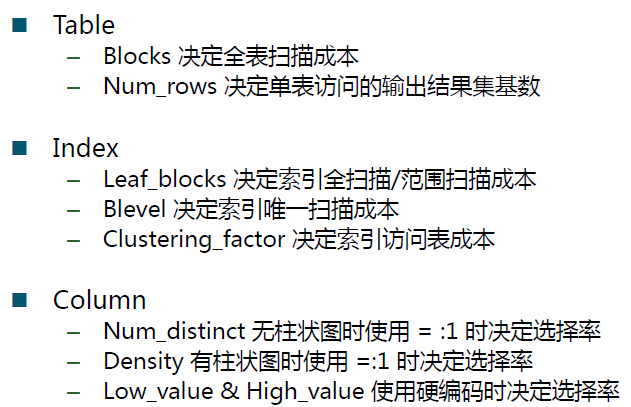
重要的统计变量
附:构建测试数据
-- 创建表与数据 CREATE TABLE EMP (EMPNO NUMBER(4) NOT NULL, ENAME VARCHAR2(10), JOB VARCHAR2(9), MGR NUMBER(4), HIREDATE DATE, SAL NUMBER(7, 2), COMM NUMBER(7, 2), DEPTNO NUMBER(2) ); INSERT INTO EMP VALUES (7369, 'SMITH', 'CLERK', 7902, TO_DATE('17-DEC-1980', 'DD-MON-YYYY'), 800, NULL, 20); INSERT INTO EMP VALUES (7499, 'ALLEN', 'SALESMAN', 7698, TO_DATE('20-FEB-1981', 'DD-MON-YYYY'), 1600, 300, 30); INSERT INTO EMP VALUES (7521, 'WARD', 'SALESMAN', 7698, TO_DATE('22-FEB-1981', 'DD-MON-YYYY'), 1250, 500, 30); INSERT INTO EMP VALUES (7566, 'JONES', 'MANAGER', 7839, TO_DATE('2-APR-1981', 'DD-MON-YYYY'), 2975, NULL, 20); INSERT INTO EMP VALUES (7654, 'MARTIN', 'SALESMAN', 7698, TO_DATE('28-SEP-1981', 'DD-MON-YYYY'), 1250, 1400, 30); INSERT INTO EMP VALUES (7698, 'BLAKE', 'MANAGER', 7839, TO_DATE('1-MAY-1981', 'DD-MON-YYYY'), 2850, NULL, 30); INSERT INTO EMP VALUES (7782, 'CLARK', 'MANAGER', 7839, TO_DATE('9-JUN-1981', 'DD-MON-YYYY'), 2450, NULL, 10); INSERT INTO EMP VALUES (7788, 'SCOTT', 'ANALYST', 7566, TO_DATE('09-DEC-1982', 'DD-MON-YYYY'), 3000, NULL, 20); INSERT INTO EMP VALUES (7839, 'KING', 'PRESIDENT', NULL, TO_DATE('17-NOV-1981', 'DD-MON-YYYY'), 5000, NULL, 10); INSERT INTO EMP VALUES (7844, 'TURNER', 'SALESMAN', 7698, TO_DATE('8-SEP-1981', 'DD-MON-YYYY'), 1500, 0, 30); INSERT INTO EMP VALUES (7876, 'ADAMS', 'CLERK', 7788, TO_DATE('12-JAN-1983', 'DD-MON-YYYY'), 1100, NULL, 20); INSERT INTO EMP VALUES (7900, 'JAMES', 'CLERK', 7698, TO_DATE('3-DEC-1981', 'DD-MON-YYYY'), 950, NULL, 30); INSERT INTO EMP VALUES (7902, 'FORD', 'ANALYST', 7566, TO_DATE('3-DEC-1981', 'DD-MON-YYYY'), 3000, NULL, 20); INSERT INTO EMP VALUES (7934, 'MILLER', 'CLERK', 7782, TO_DATE('23-JAN-1982', 'DD-MON-YYYY'), 1300, NULL, 10); CREATE TABLE DEPT (DEPTNO NUMBER(2), DNAME VARCHAR2(14), LOC VARCHAR2(13) ); INSERT INTO DEPT VALUES (10, 'ACCOUNTING', 'NEW YORK'); INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS'); INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO'); INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON '); -- 添加约束 alter table emp add constraint emp_pk primary key(empno); alter table dept add constraint dept_pk primary key(deptno); alter table dept add constraint emp_fk_dept foreign key(deptno) references dept; alter table emp add constraint emp_fk_emp foreign key(mgr) references emp; |