用sysbench压测MySQL,通过orzdba监控工具分析机器的容量
编译安装sysbench
# 安装依赖包(在上节中的mha机器上安装) yum -y install make automake libtool pkgconfig libaio-devel vim-common yum -y install mysql-devel # 编译源码安装,下载地址:https://codeload.github.com/akopytov/Sysbench/zip/1.0.5 unzip sysbench-1.0.5.zip cd sysbench-1.0.5 ./autogen.sh ./configure --with-mysql-includes=/usr/include/mysql --with-mysql-libs=/usr/lib64/mysql # 注意修改路径 make && make install |
在压测的MySQL上创建一个空的test数据库
# 已有test库的话先drop掉 drop database test; create database test; |
在压测的MySQL机开启orzdba监控工具
# 创建压测MySQL用户(不要加密码) grant all privileges on *.* to 'lyj'@'localhost' identified by ''; grant all privileges on *.* to 'lyj'@'127.0.0.1' identified by ''; # orzdba下载地址:http://pan.baidu.com/S/1migCOa8 vi orzdba #--------------------------------------------------------- my $user = 'lyj'; # -u : mysql user my $MYSQL = qq{mysql -s --skip-column-names -u$user -P$port }; #--------------------------------------------------------- chmod +x orzdba ./orzdba -lazy #------------------------------------------------------------------------------------------------------------------------------- .=================================================. | Welcome to use the orzdba tool ! | | Yep...Chinese English~ | '=============== Date : 2017-04-13 ===============' HOST: mydb1 IP: 10.245.231.202 DB : edu|lyj|lyj1|performance_schema Var : port[3306] read_only[OFF] version[5.6.35-log] binlog_format[ROW] max_binlog_cache_size[2G] max_binlog_size[500M] max_connect_errors[100] max_connections[214] max_user_connections[2800] open_files_limit[1024] sync_binlog[100] table_definition_cache[600] table_open_cache[400] thread_cache_size[10] innodb_adaptive_flushing[ON] innodb_adaptive_hash_index[ON] innodb_buffer_pool_instances[8] innodb_buffer_pool_size[128M] innodb_file_per_table[ON] innodb_flush_log_at_trx_commit[1] innodb_flush_method[O_DIRECT] innodb_io_capacity[1000] innodb_lock_wait_timeout[10] innodb_log_buffer_size[64M] innodb_log_file_size[1000M] innodb_log_files_in_group[4] innodb_max_dirty_pages_pct[60] innodb_open_files[400] innodb_read_io_threads[4] innodb_stats_on_metadata[OFF] innodb_thread_concurrency[0] innodb_write_io_threads[10] -------- -----load-avg---- ---cpu-usage--- ---swap--- -QPS- -TPS- -Hit%- ------threads------ time | 1m 5m 15m |usr sys idl iow| si so| ins upd del sel iud| lor hit| run con cre cac| 15:02:05| 0.00 0.01 0.05| 0 0 100 0| 0 0| 0 0 0 0 0| 0 100.00| 0 0 0 0| #------------------------------------------------------------------------------------------------------------------------------- |
在装sysbench机上执行压测命令
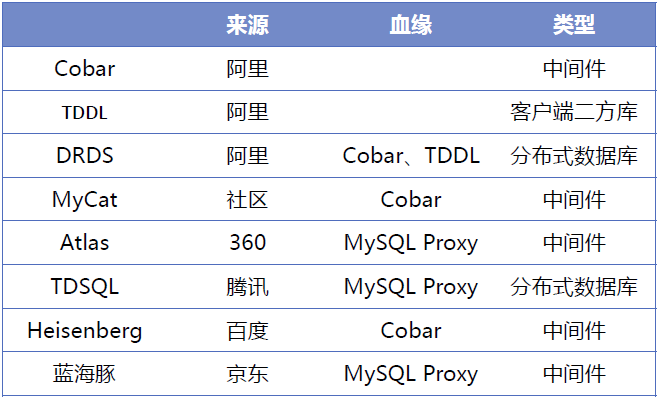
# prepare准备阶段,构建压测环境 sysbench /usr/local/share/sysbench/tests/include/oltp_legacy/select.lua \ --oltp-table-size=20000 --mysql-table-engine=innodb --db-driver=mysql \ --mysql-user=root --mysql-password=root123 --mysql-port=3306 \ --mysql-host=10.245.231.202 --mysql-db=test \ --events=0 --time=60 --oltp-tables-count=20 --report-interval=10 --threads=2 prepare #-------------------------------------------------------------------------------------------------------------------- Creating table 'sbtest1'... Inserting 20000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... Inserting 20000 records into 'sbtest2' Creating secondary indexes on 'sbtest2'... Creating table 'sbtest3'... Inserting 20000 records into 'sbtest3' ...... Creating table 'sbtest20'... Inserting 20000 records into 'sbtest20' Creating secondary indexes on 'sbtest20'... #-------------------------------------------------------------------------------------------------------------------- # 开始压测 sysbench /usr/local/share/sysbench/tests/include/oltp_legacy/select.lua \ --oltp-table-size=20000 --mysql-table-engine=innodb --db-driver=mysql \ --mysql-user=root --mysql-password=root123 --mysql-port=3306 \ --mysql-host=10.245.231.202 --mysql-db=test \ --events=0 --time=60 --oltp-tables-count=20 --report-interval=10 --threads=2 run #-------------------------------------------------------------------------------------------------------------------- Running the test with following options: Number of threads: 2 Report intermediate results every 10 second(s) Initializing random number generator from current time Initializing worker threads... Threads started! [ 10s ] thds: 2 tps: 5987.78 qps: 5987.78 (r/w/o: 5987.78/0.00/0.00) lat (ms,95%): 0.41 err/S: 0.00 reconn/S: 0.00 [ 20s ] thds: 2 tps: 7711.35 qps: 7711.35 (r/w/o: 7711.35/0.00/0.00) lat (ms,95%): 0.35 err/S: 0.00 reconn/S: 0.00 [ 30s ] thds: 2 tps: 7751.22 qps: 7751.22 (r/w/o: 7751.22/0.00/0.00) lat (ms,95%): 0.35 err/S: 0.00 reconn/S: 0.00 [ 40s ] thds: 2 tps: 7710.81 qps: 7710.81 (r/w/o: 7710.81/0.00/0.00) lat (ms,95%): 0.39 err/S: 0.00 reconn/S: 0.00 [ 50s ] thds: 2 tps: 10138.07 qps: 10138.07 (r/w/o: 10138.07/0.00/0.00) lat (ms,95%): 0.31 err/S: 0.00 reconn/S: 0.00 [ 60s ] thds: 2 tps: 8729.18 qps: 8729.18 (r/w/o: 8729.18/0.00/0.00) lat (ms,95%): 0.33 err/S: 0.00 reconn/S: 0.00 SQL statistics: queries performed: read: 480290 write: 0 other: 0 total: 480290 transactions: 480290 (8004.05 per sec.) queries: 480290 (8004.05 per sec.) ignored errors: 0 (0.00 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 60.0012s total number of events: 480290 Latency (ms): min: 0.12 avg: 0.25 max: 8.10 95th percentile: 0.38 sum: 119006.64 Threads fairness: events (avg/stddev): 240145.0000/594.00 execution time (avg/stddev): 59.5033/0.00 #-------------------------------------------------------------------------------------------------------------------- |
通过orzdba监控工具分析查看机器的容量
分库分表架构设计
问题:在订单表中(分库分表),有70%查询是通过主键和userId字段查询(userId是分库分表策略字段),有20%要通过order_num(订单号)查数据。
1. 请问order_num(订单号)要怎么设计才能快速找到订单记录是在哪个库的哪个表?
在订单号order_num中加入库序号和表序号,通过userid可以算出库序号和表序号,计算公式如下:中间变量=userId%(库数量*每个库的表数量)
库序号=中间变量/每个库的表数量
表序号=中间变量%每个库的表数量
2. 有10%是非主键字段(比如:字段、渠道、商品,档期,品牌,收件人信息、金额等字段)去查记录,非主键字段要怎么设计才能快速定位到记录?
可以建立非主键字段索引表,索引表是主建与非主键字段的对应关系表,可根据非主键进行哈希取模,放到分库里面。在使用非主键字段进行查询时,先查出非主键对应的主键,再根据主键去对应的库表中查询订单数据。
杂记
容量评估4个重要指标:
- LOAD:服务器的负载,在Linux中可以通过top命令查看
load average - CPU:CPU的使用率,在Linux中可以通过
top和cat /proc/Stat命令查看 - QPS:
Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。 - TPS:
Transactions PerSecond,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息来估计得分。客户机使用加权协函数平均方法来计算客户机的得分,测试软件就是利用客户机的这些信息使用加权协函数平均方法来计算服务器端的整体TPS得分。
容量评估-QPS评估
峰值QPS=(总的PV * 80%)/(60 * 60 * 24 * 20%) 机器数=总的峰值QPS/压测得出的单台机器极限QPS |
MySQL构架设计
读写分离方案
- 海量数据的存储及访问,通过对数据库进行读写分离,来提升数据的处理能力。读写分离它的方案特点是数据库产生多个副本,数据库的写操作都集中到一个数据库上,而一些读的操作呢,可以分解到其它数据库上。这样,只要付出数据复制的成本,就可以使得数据库的处理压力分解到多个数据库上,从而大大提升数据处理能力。
- 优点:由于所有的数据库副本,都有数据的全拷贝,因此所有的数据库特性都可以实现,部分机器当机不影响系统的使用。
- 缺点:数据的复制同步是一个问题,要么采用数据库自身的复制方案,要么自行实现数据复制方案。需要考虑数据的迟滞性,一致性方面的问题。
数据分区(分库)方案
- 原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。而分区的方案就是把某一个或某几张相关的表的数据放在一个独立的数据库上,这样就可以把CPU、内存、文件IO、网络IO分解到多个机器中,从而提升系统处理能力。
- 优点:不存在数据库副本复制,性能更高。
- 缺点:分区策略必须经过充分考虑,避免多个分区之间的数据存在关联关系,每个分区都是单点,如果某个分区宕机,就会影响到系统的使用。
数据分表方案
- 不管是上面的读写分离方案还是数据分区方案,当数据量大到一定程度的时候,都会导致处理性能的不足,这个时候就没有办法了,只能进行分表处理。也就是把数据库当中数据根据按照分库原则分到多个数据表当中,这样,就可以把大表变成多个小表,不同的分表中数据不重复,从而提高处理效率。
- 优点:数据不存在多个副本,不必进行数据复制,性能更高。
- 缺点:分表之间的数据很少进行集合运算;分表都是单点,如果某个分表宕机,如果使用的数据不在此分表,不影响使用。
当单库单表无法满足大量写的请求时,需进行分表,分表方式有以下两种:
- 同库分表:所有的分表都在一个数据库中,由于数据库中表名不能重复,因此需要把数据表名起成不同的名字。
优点:由于都在一个数据库中,公共表,不必进行复制,处理更简单
缺点:由于还在一个数据库中,CPU、内存、文件IO、网络IO等瓶颈还是无法解决,只能降低单表中的数据记录数。表名不一致会导后续的处理复杂。 - 不同库分表:由于分表在不同的数据库中,这个时候就可以使用同样的表名。
优点:CPU、内存、文件IO、网络IO等瓶颈可以得到有效解决,表名相同,处理起来相对简单
缺点:公共表由于在所有的分表都要使用,因此要进行复制、同步。
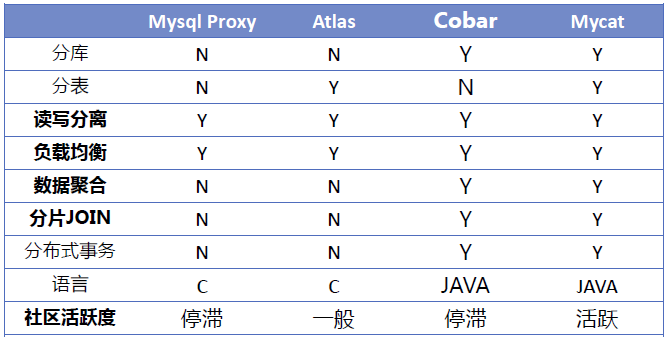
开发-分库分表路线分析
- 一种是对用户透明的方案,即用户只用像普通的JDBC数据源一样访问即可,由框架解决所有的数据访问问题。另外一种是应用层解决,具体一般是在Dao层进行封装。
- JDBC层方案
- 优点:开发人员使用非常方便,开发工作量比较小;可以实现数据库无关。
- 缺点:框架实现难度比较大,性能不一定能做到最优。
- 同样是JDBC方案,也有两种解决方案,一种是有代理模式,一种是无代理模式。
- 有代理模式,有一台专门的代理服务器,来接收用户请求,然后发送请求给数据库集群中的数据,并对数据进行汇集后再提交给请求方。
- 无代理模式,就是说没有代理服务器,集群框架直接部署在应用访问端。
- 有代理模式,能够提供的功能更强大,甚至可买提供中间库进行数据处理,无代理模式处理性能较强有代理模式少一次网络访问,相对来说性能更好,但是功能性不如有代理模式。
- DAO层方案
- 优点:开发人员自由度非常大,性能调优更精准。
- 缺点:开发人员在一定程度上受影响,与具体的Dao技术实现相关,较难做到数据库无关。
- 由于需要对SQL脚本进行判断,然后进行路由,因此DAO层优化方案一般都是选用iBatis或Spring JdbcTemplate等方案进行封装,而对于Hibernate等高度封装的OR映射方案,实现起来就非常困难了。
分库分表带来的限制
- 条件查询、分页查询受到限制,查询必须带上分库分表所带上的id
- 事务可能跨多个库,数据一致性无法通过本地事务实现,无法使用外键
- 分库分表规则确定以后,扩展变更规则需要迁移数据
业务痛点:
业内解决方案: