服务器参数调优,有哪些关键点?
MySQL性能调优有哪些关键点/经验?
应用访问的优化
- 减少数据访问(减少磁盘访问),如尽量让应用去访问数据库的缓存服务器(Redis/Memcached),性能提升1~1000倍,优化成本低
- 返回更少数据(减少网络传输或磁盘访问),性能提升1~100倍,优化成本低
- 减少交互次数(减少网络传输),性能提升1~10倍,优化成本低
服务器硬件的选型
跟据业务需求来最终选择确定MYSQL服务器的配件配置,如CPU的processor数,内存的大小,以及SSD+SAS的组合(活跃数据/随机访问的data文件放到SSD盘中,冷数据/顺序访问的binlog文件放到SAS磁盘中)等。
操作系统优化
使用推荐的Linux
- CentOS
- Redhat
- SUSE
关闭SWAP
注意: 在CentOS 6.4及更新版本的内核中设置vm.swappiness=0,有可能会导致MySQL数据库所在的系统出现内存溢出(OOM),建议将vm.swappiness设置成1
# 在CentOS 5.x/6.x中 vi /etc/sysctl.conf ---------------------------------------------------------- vm.swappiness=1 ---------------------------------------------------------- # CentOS 7.x中 ## 查找到存在vm.swappiness参数的配置文件 find /usr/lib/tuned -name '*.conf' -type f -exec grep "vm.swappiness" {} \+ ---------------------------------------------------------- /usr/lib/tuned/latency-performance/tuned.conf:vm.swappiness=10 /usr/lib/tuned/throughput-performance/tuned.conf:vm.swappiness=10 /usr/lib/tuned/virtual-guest/tuned.conf:vm.swappiness = 30 ---------------------------------------------------------- # 把以上3个文件中的vm.swappiness的值都修改为0或1 |
关闭NUMA
NUMA: 非统一内存访问架构(Non Uniform Memory Access Architecture)。
NUMA是一种用于多处理器的电脑记忆体设计,内存访问时间取决于处理器的内存位置。 在安装有多个CPU的计算机中,NUMA硬件可以通过将专用内存与CPU配对来显著提高性能。在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。SMP: 共享存储型多处理机(Shared Memory mulptiProcessors), 也称为对称型多处理机(Symmetry MultiProcessors)。
SMP模式将多个处理器与一个集中的存储器相连。在SMP模式下,所有处理器都可以访问同一个系统物理存储器,这就意味着SMP系统只运行操作系统的一个拷贝。因此SMP系统有时也被称为一致存储器访问(UMA)结构体系,一致性意指无论在什么时候,处理器只能为内存的每个数据保持或共享唯一一个数值。很显然,SMP的缺点是可伸缩性有限,因为在存储器接口达到饱和的时候,增加处理器并不能获得更高的性能。
SMP和NUMA架构对比图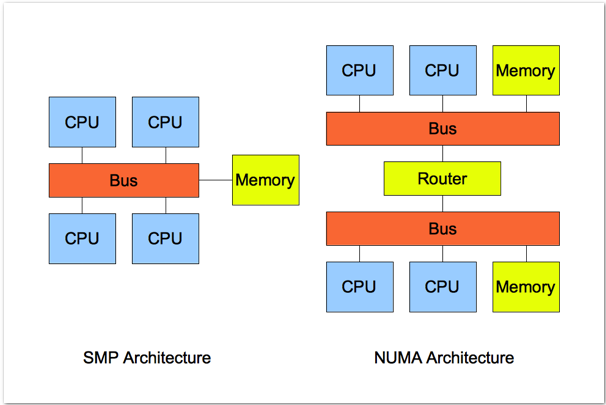
MySQL采用了线程模式,对于NUMA特性的支持并不好,如果单机只运行一个MySQL实例,建议关闭NUMA,方法有以下几种:
1.BIOS中设置关闭(推荐)
2.OS内核中设置关闭# Centos 7参照以下方法
grubby --update-kernel=ALL --args="numa=off"
# 若要移除上面的修改,使用以下命令
grubby --update-kernel=ALL --remove-args="numa=off"
3.启动MySQL时关闭numactl --interleave=all mysqld
如果单机运行多个MySQL实例,可以将MySQL绑定在不同的CPU节点上,并且采用绑定的内存分配策略,强制在本节点内分配内存,这样既可以充分利用硬件的NUMA特性,又避免了单实例MySQL对多核CPU利用率不高的问题。详细可参考:MySQL单机多实例方案
网卡优化
1.双网卡做成bond0
2.调整网络参数# 查看所有可调参数命令是sysctl -a,根据服务器配置调整以下参数
vi /etc/sysctl.conf
----------------------------------------------------------
net.core.rmem_max = 4194304
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_wmem = 4096 16384 4194304
----------------------------------------------------------
磁盘调度设置
MYSQL服务器IO调度算法一般要设置成NOOP或Deadline,推荐使用是Deadline算法。
- NOOP算法:全写为No Operation。 该算法实现了最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。
- CFQ算法:全写为Completely Fair Queuing。 该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
- DEADLINE:在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。
- Anticipatory算法:CFQ和DEADLINE考虑的焦点在于满足零散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。
查看和修改系统IO的调度方法# 查看操作系统的IO调度方法(CentOS Linux)
dmesg | grep -i scheduler
----------------------------------------------------------
[ 1.508820] io scheduler noop registered
[ 1.508827] io scheduler deadline registered (default)
[ 1.508850] io scheduler cfq registered
----------------------------------------------------------
cat /sys/block/sda/queue/scheduler
# 临地更改I/O调度方法
echo deadline > /sys/block/sda/queue/scheduler
# 永久的更改I/O调度方法(重启后生效)
## Centos 7参照以下方法
grubby --info=ALL
grubby --update-kernel=ALL --args="elevator=deadline"
## Centos 5/6参照以下方法
vi /boot/grub/grub.conf
----------------------------------------------------------
# 添加elevator=deadline到下行
kernel /vmlinuz-2.6.18-274.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
----------------------------------------------------------
使用推荐的文件系统
1.推荐用xfs/ext4
2.挂载盘时添加noatime和nobarrier参数,设置方法如下:vi /etc/fstab
----------------------------------------------------------
/dev/mapper/cl-root / xfs defaults,noatime,nobarrier 0 0
----------------------------------------------------------
当文件被创建,修改和访问时,Linux系统会记录这些时间信息。当系统的读文件操作频繁时,记录文件最近一次被读取的时间信息,将是一笔不少的开销。所以,为了提高系统的性能,我们可以在读取文件时不修改文件的
atime属性。可以通过在加载文件系统时使用noatime选项来做到这一点。当以noatime选项加载(mount)文件系统时,对文件的读取不会更新文件属性中的atime信息。设置noatime的重要性是消除了文件系统对文件的写操作,文件只是简单地被系统读取。由于写操作相对读来说要更消耗系统资源,所以这样设置可以明显提高服务器的性能。注意wtime信息仍然有效,任何时候文件被写,该信息仍被更新。现在的很多文件系统会在数据提交时强制底层设备刷新cache,避免数据丢失,称之为
write barriers。 但是,其实我们数据库服务器底层存储设备要么采用RAID卡,RAID卡本身的电池可以掉电保护;要么采用Flash卡,它也有自我保护机制,保证数据不会丢失。 所以我们可以安全的使用nobarrier挂载文件系统。对于ext3、ext4和reiserfs文件系统可以在mount时指定barrier=0;对于xfs可以指定nobarrier选项。
数据库优化
实例优化,修改参数
innodb_buffer_pool_size # 相当于Oracle的SGA,一般设置为物理内存的70%-80%,设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而减低sql查询的效率 innodb_thread_concurrency # 一般设置成小于CPU的核心数 query_cache_type = 0 # =0 关闭结果集缓存 query_cache_size =0 # =0 关闭结果集缓存 max_used_connections # 最大的连接数,根据应用实际情况来设置 interactive_timeout # 应用交互超时等待 wait_timeout # 连接池超时等待 innodb_io_capacity=20000 # innodb IO容量的设置,一般设置成IOPS的75%左右 innodb_flush_log_at_trx_commit # =1 每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘 sync_binlog # =1 与innodb_flush_log_at_trx_commit=1 双1设置,提高数据安全性 innodb_log_file_size # 日志文件的大小,日志放到SSD建议设4-8G,放到SAS盘建议设成1-2G innodb_log_files_in_group # 日志文件的数量 innodb_flush_method # 有三个值:fdatasync(默认),O_DSYNC,O_DIRECT,详细 innodb_max_dirty_pages_pct # =50 用来控制在 InnoDB Buffer Pool 中可以不用写入数据文件中的Dirty Page的比例(已经被修但还没有从内存中写入到数据文件的脏数据) Innodb_flush_neighbors # =0或1 相邻的数据合并,SSD盘关闭此设置,SAS盘开启此设置 transaction_isolation # 事务隔离级别,生产环境设置为READ-COMMITTED |
内存分配All thread buffer = # 会话/线程级内存分配总和
max_threads * ( # 当前活跃连接数
read_buffer_size # 顺序读缓冲,提高顺序读效率
+ read_rnd_buffer_size # 随机读缓冲,提高随机读效率
+ sort_buffer_size # 排序缓冲,提高排序效率
+ join_buffer_size # 表连接缓冲,提高表连接效率
+ binlog_cache_size # 二进制日志缓冲,提高二进制日志写入效率
+ tmp_table_size # 内存临时表,提高临时表存储效率
+ thread_stack # 线程堆栈,暂时寄存SQL语句/存储过程
+ thread_cache_size # 线程缓存,降低多次反复打开线程开销
+ net_buffer_length # 线程持连接缓冲以及读取结果缓冲
+ bulk_insert_buffer_size # MyISAM表批量写入数据缓冲
)
global buffer = # 全局内存分配总和
innodb_buffer_pool_size # InnoDB高速缓冲,行数据、索引缓冲,以及事务锁、自适应哈希等
+ innodb_additional_mem_pool_size # InnoDB数据字典额外内存,缓存所有表数据字典
+ innodb_log_buffer_size # InnoDB REDO日志缓冲,提高REDO日志写入效率
+ key_buffer_size # MyISAM表索引高速缓冲,提高MyISAM表索引读写效率
+ query_cache_size # 查询高速缓存,缓存查询结果,提高反复查询返回效率
+ table_cahce # 表空间文件描述符缓存,提高数据表打开效率
+ table_definition_cache # 表定义文件描述符缓存,提高数据表打开效率
innodb_flush_method参数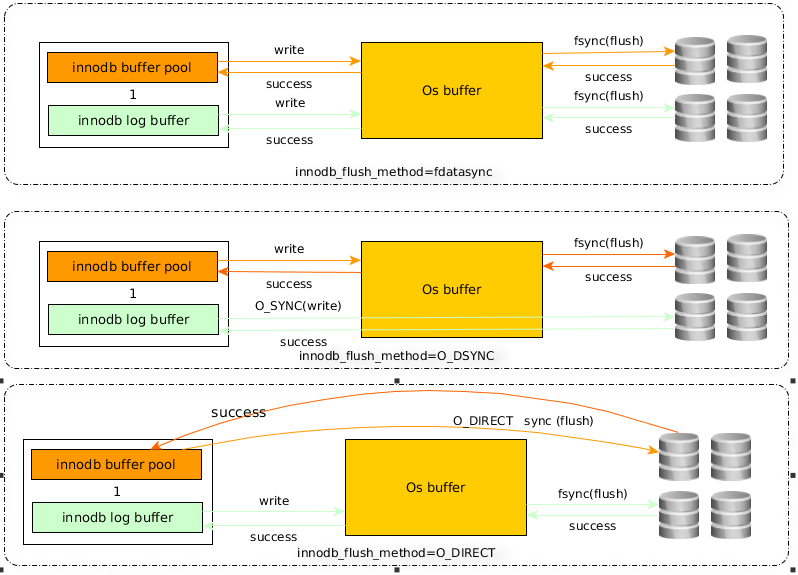
SQL优化
- 禁止多于3表join,尽量用单表查询
- SELECT语句只获取需要的字段,禁止使用
select * from语句,这是有效防止新增字段对应用逻辑的影响,还能减少对性能的影响 - InnoDB表避免使用
COUNT(*)操作,计数统计实时要求较强可以使用memcache或者redis,非实时统计可以使用单独统计表,定时更新 - 避免多余的排序。使用
GROUP BY时,默认会进行排序,当你不需要排序时,可以使用order by null,例如select a.OwnerUserID,count(*) cnt from DP_MessageList a group by a.OwnerUserID order by null; - 新增排序要求:不鼓励在DB里排序,尽量放到app server上排序,app server有上百台,而DB仅仅个位数的服务器数量,排序都在DB,会把DB压垮
- 全模糊查询无法使用INDEX,应当尽可能避免,如:select * from table where name like ‘%hotgirl%;’,不建议使用%前缀模糊查询,例如LIKE ‘%weibo’。
- 使用IN代替OR。SQL语句中IN包含的值不应过多,应少于1000个
- 禁止隐式转换。数值类型禁止加引号;字符串类型必须加引号
- 禁止使用负向查询,例如not in、!=、not like
- select for update语法,必须重点review流程
- 尽量少用
or,当where子句中存在多个条件以“或”并存的时候,MySQL的优化器并没有很好的解决其执行计划优化的问题,再加上MySQL特有的SQL与Storage分层架构方式,造成了其性能比较低下,很多时候使用union all或者union(必要的时候)的方式来代替or会得到更好的效果 - 尽量用
union all代替union,union和union all的差异主要是前者需要将两个(或者多个)结果集合并后再进行唯一性过滤操作,这就会涉及到排序,增加大量的CPU运算,加大资源消耗及延迟。所以当我们可以确认不可能出现重复结果集或者不在乎重复结果集的时候,尽量使用union all而不是union - 尽量早过滤,这一优化策略其实最常见于索引的优化设计中(将过滤性更好的字段放得更靠前),尽量用join代替子查询
- 禁止在主库上执行后台管理和统计类功能的QUERY,必要时申请统计类从库
查看SQL执行计划示例mysql> explain
-> select id,name from t2 where id=5;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t2 | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
mysql> explain
-> select id,name from t2 where name='C';
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
| 1 | SIMPLE | t2 | ref | name | name | 33 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
1 row in set (0.00 sec)
索引设计
覆盖索引
- 查询谓词都能够通过index进行扫描
- 排序谓词都能够利用index的有序性
- index包含了查询所需要的所有字段
不能使用索引
- 不要给选择率低的字段建索引(通过索引扫描的记录数超过30%,变成全表扫描)
- 联合索引中:第一个索引列使用范围查询,第一个查询条件不是最左索引列
- Like查询条件列最左以通配符% 开始
- 两个独立索引,其中一个用于检索,一个用于排序(索引不是越多越好,尽量合并索引)
- 表关联字段类型不一样(也包括长度不一样)
- 索引字段条件上使用函数
- 不要使用外健约束