感知事务提交的效果,给出SQL演示:
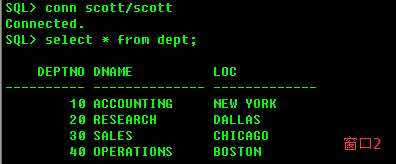
在一个会话里发出一条DML语句(比如插入一条数据),不要提交,在另一个会话里面进行查询,看是否能够查到插入的数据?
不能看到插入的数据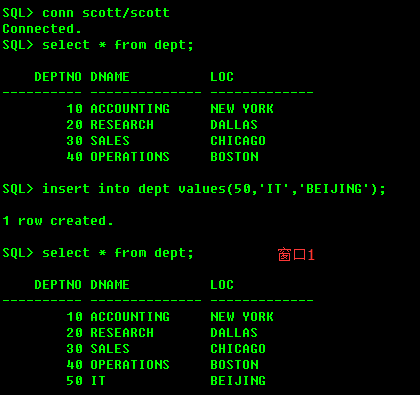
在第一个会话中发出commit,在另一个会话里面进行查询,看是否能够查到修改过的数据。
可以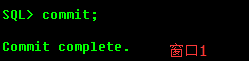
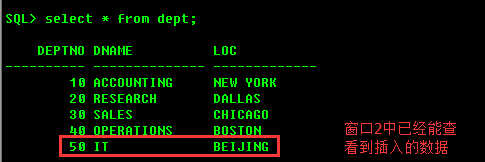
同时思考一个问题,在第一个会话插入一条数据之后,不要提交,为什么别的会话查询不到,而当前会话可以查到?
这里的场景考虑到事务隔离级别:Oracle数据库支持READ COMMITTED 和SERIALIZABLE这两种事务隔离级别。并且oracle默认采用的是持READ COMMITTED隔离级别,也就是说一个会话只能读取其他事务已提交的更新结果,否则,发生等待,但是其他会话可以修改这个事务中被读取的记录,而不必等待事务结束,显然,在这种隔离级别下,一个事务中的两个相同的读取操作,其结果可能不同。
计算出你的数据库当前SGA和PGA的大小,给出SQL演示。
SQL> show sga Total System Global Area 4375998464 bytes Fixed Size 2260328 bytes Variable Size 838861464 bytes Database Buffers 3523215360 bytes Redo Buffers 11661312 bytes SQL> select sum(PGA_USED_MEM) PGA_USED_MEM from v$process; PGA_USED_MEM ------------ 41467768 |
说出服务器进程和实例后台进程有什么区别?
实例的一半是内存,实例的另外一半就是进程。与内存不同,进程都是实实在在的存在,你可以看得见(不过摸不着)。通过相关进程,Oracle实现数据库与实例的连通;通过相关进程,Oracle实现数据库与实例的互动;通过相关进程,Oracle实现对Oracle数据库的应用。
Oracle进程分为两类:服务器进程(Server Process)和后台进程(Background Process),下面分别进行区分。
服务器进程
Oracle的服务器进程有Oracle实例自动创建,用来处理连接到实例的客户端进程发出的请求,用户必须通过连接到Oracle的服务器进程来获取数据库中的信息。对于专用服务器模式,客户端进程和Oracle服务器进程是一一对应的,而在共享服务器模式下,一个Oracle服务器进程可能同时服务多个客户端进程。
服务器进程主要用来执行下列的任务:
- 解析、执行客户端提交的SQL语句。
- 从磁盘数据文件中读取必须的数据块到SGA得数据缓存区。
- 以适当形式返回SQL语句执行结果。
实例后台进程
后台进程是管理实例的,是实例的内存结构与文件系统之间的桥梁。像Oracle数据库这么庞大的结构,要保持高效、稳定并且具有良好的性能,只有几个经纪人显然不行的,因此各项标准服务都由特定进程专门处理,比如写数据文件要有DBWR进程,写归档文件要有ARCH进程等。由Oracle在后台自动启动、管理和维护,因此这些进程才被称为后台进程。
说说你对数据库实例的理解,它的主要作用是什么?
实例是由操作系统中的一组内存区和一系列的操作系统进程组成,数据库则是指Oracle保存数据的一系列物理结构和逻辑结构,用户在访问Oracle数据库时主要是在与实例打交道,由实例访问数据库,并返回相应的操作结果。
最简单的Oracle数据库结构是由一个实例和一个数据库组成,不过对于RAC(或OPS)架构的Oracle数据库,一个数据库会对应多个实例。
在Oracle数据库,实例和数据库可以理解成两个相互间有关联的独立个体,每个数据库都至少有一个与之对应的实例(对于OPS/RAC架构的Oracle数据库,一个数据库会对应多个实例),每个实例在其生命周期内同时只能对应一个数据库。所谓的启动Oracle数据库时,实际上是连接到实例,说的更直白点儿,就是连接到操作系统的某些进程,并由这些进程访问处理内存中的对象,至于这些对象时如何从磁盘被读取到内存,那正是实例所做的工作。
Oracle中的实例有内存结构和进程结构两大部分组成。
创建一个分区表,并插入一些数据,同时查询出每个分区的数据。
create table tab_pat (col1 number,col2 varchar2(30)) partition by range(col1)( partition tab_pat_01 values less than(20000), partition tab_pat_02 values less than(40000), partition tab_pat_03 values less than(60000), partition tab_pat_04 values less than(80000), partition tab_pat_05 values less than(maxvalue) ); insert into tab_pat select object_id,object_name from all_objects; commit; SQL> select count(*) from tab_pat; COUNT(*) ---------- 68327 SQL> select count(*) from tab_pat partition (tab_pat_01); COUNT(*) ---------- 11699 SQL> select count(*) from tab_pat partition (tab_pat_02); COUNT(*) ---------- 19993 SQL> select count(*) from tab_pat partition (tab_pat_03); COUNT(*) ---------- 19999 SQL> select count(*) from tab_pat partition (tab_pat_04); COUNT(*) ---------- 15842 SQL> select count(*) from tab_pat partition (tab_pat_05); COUNT(*) ---------- 794 SQL> select * from tab_pat partition (tab_pat_05) where rownum<10; COL1 COL2 ---------- ------------------------------ 80001 SDO_NETWORK_MANAGER_T 80004 SDO_NETWORK_MANAGER_T 80005 SDO_NODE_T 80007 SDO_NODE_T 80008 SDO_LINK_T 80019 SDO_NETWORK_T 80010 SDO_LINK_T 80011 SDO_PATH_T 80013 SDO_PATH_T |
创建一个视图,并给出一个查询语句。
create view vi_obj as select col1 object_id,col2 object_name from tab_pat where col1>=85000; SQL> select count(*) from vi_obj; COUNT(*) ---------- 358 |
在当前用户下创建一个同义词,用于查询scott用户下的dept表,并给出一个查询语句。
conn / as sysdba grant select any table to hr; conn hr/hr create synonym dept for scott.dept; select * from dept; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON 50 IT BEIJING |
创建一个sequence,并给出一个获得sequence号的语句。
create sequence emp_seq start with 1000 increment by 1 nocache nocycle; SQL> select emp_seq.nextval from dual; NEXTVAL ---------- 1000 SQL> select emp_seq.currval from dual; CURRVAL ---------- 1000 |
创建一个指向本地数据库的dblink,并通过dblink查询一个表中的数据。
SQL> conn / as sysdba Connected. SQL> grant create database link to hr; Grant succeeded. conn hr/hr create database link scott connect to scott identified by scott using 'orcl'; SQL> select * from scott.dept@scott; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON 50 IT BEIJING |
创建一个表空间,并在这个表空间上创建一张表。
conn / as sysdba create tablespace test_ts datafile '/u01/app/oracle/oradata/orcl/test_ts01.dbf' size 50m; conn hr/hr create table test1 (id number,name varchar2(10)) tablespace test_ts; |
将数据库设置为归档模式,并进行一次日志切换,观察归档文件的产生。
SQL> conn / as sysdba Connected. SQL> archive log list; Database log mode No Archive Mode Automatic archival Disabled Archive destination /u01/app/oracle/11.2.0.4/db_1/dbs/arch Oldest online log sequence 4 Current log sequence 6 SQL> shutdown immediate Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 4375998464 bytes Fixed Size 2260328 bytes Variable Size 905970328 bytes Database Buffers 3456106496 bytes Redo Buffers 11661312 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> ! mkdir /u01/app/oracle/archive SQL> alter system set log_archive_dest='/u01/app/oracle/archive'; SQL> alter database open; Database altered. SQL> archive log list; SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/archive Oldest online log sequence 4 Next log sequence to archive 7 Current log sequence 7 SQL> alter system switch logfile; System altered. SQL> ! ls -l /u01/app/oracle/archive total 248 -rw-r----- 1 oracle oinstall 253952 Jul 18 16:57 1_7_949653805.dbf |
说说你是如何理解commit和checkpoint的。
下面这些操作将会触发checkpoint事件:
- 日志切换,通过ALTER SYSTEM SWITCH LOGFILE。
- DBA发出checkpoint命令,通过ALTER SYSTEM checkpoint。
- 对数据文件进行热备时,针对该数据文件的checkpoint也会进行,ALTER TABLESPACE TS_NAME BEGIN BACKUP/END BACKUP。
- 当运行ALTER TABLESPACE/DATAFILE READ ONLY的时候。
- SHUTDOWN命令发出时。
checkpoint会触发DBWR进程(数据库写进程),将脏数据块写到数据文件中,而commit触发LGWR(日志写进程),将redo日志缓存写到redo日志文件中。
如果DBWR进程要将事务的结果写入数据文件,但发现要写入的脏数据块相关的重做信息仍然处于重做日志缓存中,它将通知oracle启动LGWR进程,先将这些重做信息写入重做日志文件,直到重做信息全部被写入后,DBWR进程才开始将脏缓存写入数据文件。
说说你是如何理解redo和undo的作用的。
redo 是利用日志恢复已提交的事务;undo是利用undo表空间里的前镜像恢复未提交的但已修改的事务。
REDO记录transaction logs,分为online和archived,以恢复为目的。比如,机器停电,那么在重起之后需要online redo logs去恢复系统到失败点。比如,磁盘坏了,需要用archived redo logs和online redo logs区恢复数据。比如,truncate一个表或其他的操作,想恢复到之前的状态,同样也需要。
REDO是为了重新实现你的操作,而UNDO相反,是为了撤销你做的操作,比如你得一个TRANSACTION执行失败了或你自己后悔了,则需要用 ROLLBACK命令回退到操作之前。回滚是在逻辑层面实现而不是物理层面,因为在一个多用户系统中,数据结构,blocks等都在时时变化,比如我们 INSERT一个数据,表的空间不够,扩展了一个新的EXTENT,我们的数据保存在这新的EXTENT里,其它用户随后也在这EXTENT里插入了数据,而此时我想ROLLBACK,那么显然物理上讲这EXTENT撤销是不可能的,因为这么做会影响其他用户的操作。所以,ROLLBACK是逻辑上回滚,比如对INSERT来说,那么ROLLBACK就是DELETE了。
对于下面的操作,说一说redo和undo分别是在哪个阶段产生的
语句:update t set id=1 where id=2
- 当发出这条update语句后,oracle先将更改前后信息写进redo(当满足一定条件后由日志写进程写入日志文件)
- 然后将更新前得数据镜像copy到undo中。
- 用户rollback后,oracle 将undo中的数据覆盖回去。T表中的id=1
- 用户commit后,oracle可以根据redo 的信息进行数据恢复。T表中的id=2
杂记
数据库中的对象
# 查看数据库中所有对象的类型 select distinct object_type from dba_objects order by 1; # 以下是一些常用的对象类型 INDEX PARTITION SEQUENCE TABLE PARTITION SCHEDULE PROCEDURE LOB PACKAGE TRIGGER DIRECTORY MATERIALIZED VIEW TABLE INDEX SYNONYM VIEW FUNCTION JOB DATABASE LINK |